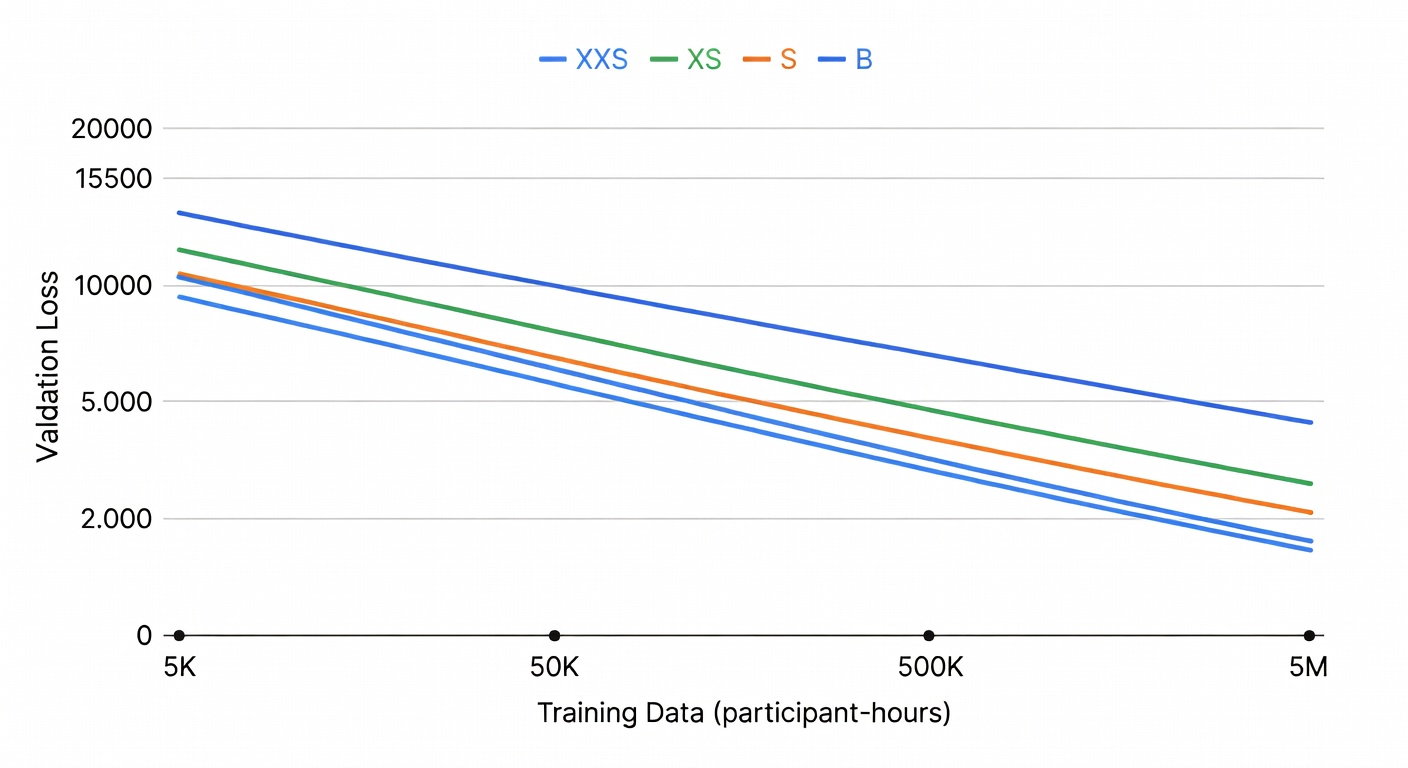
SensorFM is a 1.2B parameter audio foundation model pretrained on 1.5 million hours of audio — the kind of scale that makes you stop and rethink what is possible with sound.
The results are striking: 91.5% accuracy on AudioSet, 95.2% on ESC-50 with just 10-shot learning. Not 100-shot. Not fine-tuned. Ten examples and it understands.
The scaling law is beautifully linear. More data equals better understanding. No tricks, no architectural hacks — just scale and patience.
What makes this matter: audio has been the neglected sibling of text and image in the foundation model race. Everyone talks about LLMs and diffusion models. But sound is how we experience the world — speech, music, environmental cues, health signals.
SensorFM proves that audio foundation models can scale the same way. The linear relationship between training data and downstream performance means we can predictably improve understanding by adding more diverse sound.
For builders, this is a signal. The infrastructure for audio AI is reaching the tipping point where product-quality experiences become possible. Not demos. Real products.